3D Reconstruction for Stereo Endoscopic Video
13 Dec 2019Stereoscopic endoscope is used for da Vinci robotic surgery. Some surgeons also use them in laparoscopic surgeries. It provides depth perception to the users, who either sit in the robot console, or watch a stereoscopic monitor with a pair of shutter glass.
It has been a long desire to reconstruct the 3D surgical scene. With this capability, computers are able to better understand the procedure, to provide analytics and generate artificial intelligence. In addition, it can improve the visualization of endoscopy, in combination with mixed reality technologies.
Throughout my study, I have attempted to tackle the 3D reconstruction of endoscopic video using two methods, via traditional computer vision algorithms and deep learning.
Traditional Approach
The key step to 3D reconstruct from stereo images is to compute the disparity between the image pair. The depth of each pixel could be explicitly calculated from the disparity value, given the camera intrinsic parameters. In ARAMIS, we use the traditional approach to calculate the disparity map, semi-global matching algorithm (SGM). In SGM, the algorithm minimizes the matching cost and the disparity smoothness between adjacent pixels.
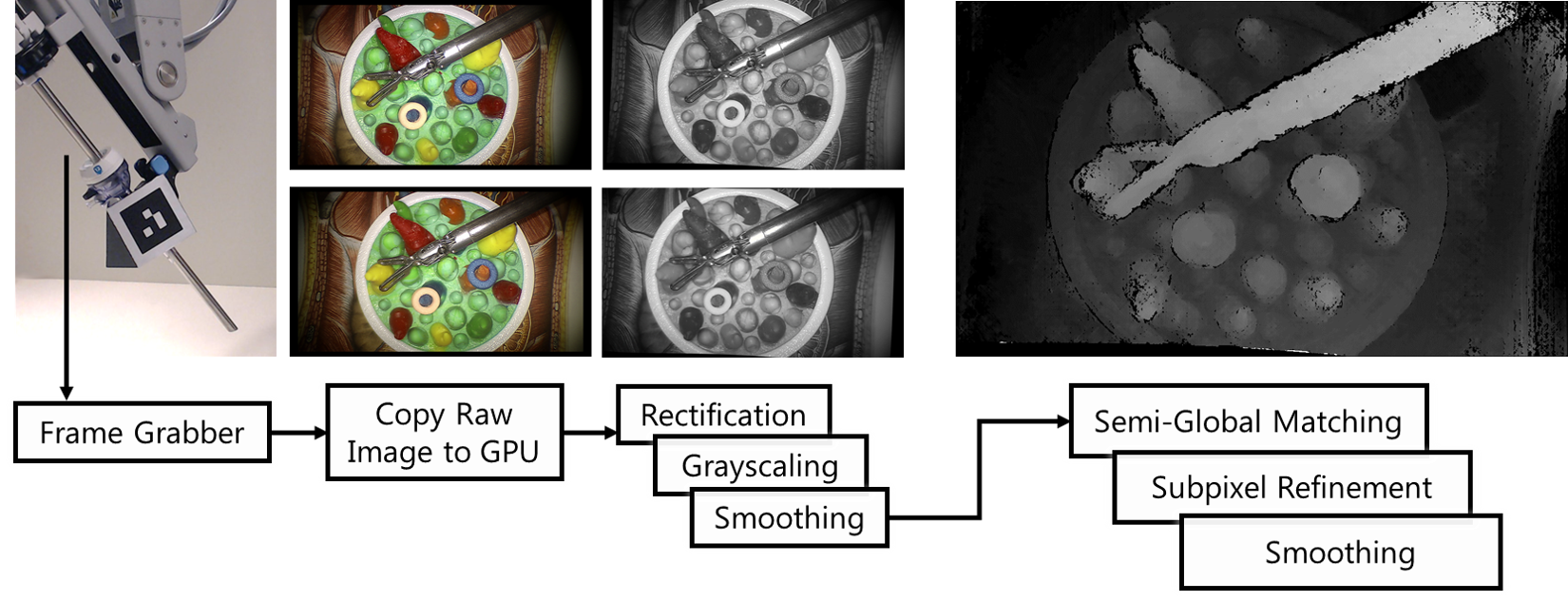
SGM works reasonably well and reasonably fast. However, to use it for real-time augmented reality visualization, the disparity calculation needs to be done within tens of milliseconds. We decide to use parallel programming (CUDA) to further optimize the time efficiency. Parallel programming can drastically help with the Cost Aggregation, which is done individually for each pixel across the image. As a side effect, all the preprocessing of the image also took advantage of the paralleled computation, e.g. image smoothness and grayscaling.
In the end, our implementation achieves 16.7 milliseconds to compute a dense disparity map for 1080x680 input images. With real-time streaming and rendering, ARAMIS was evaluated to be helpful for users to perform laparoscopic tasks.
More details about the implementation is available in our recently published MICCAI paper: ARAMIS, which I presented in Shenzhen, China.

Deep Learning?
Together with Xiran Zhang and Maxwell Li, we participated in the 2019 MICCAI EndoVis challenge: the SCARED sub-challenge. SCARED stands for Stereo Correspondence and Reconstruction of Endoscopic Data. One particular issue with stereo reconstruction for medical scene is the lack of data with ground truth. Previous popular datasets are KITTI for autonomous driving and Middlebury Stereo Dataset for general scene. Thank Intuitive Surgical for collecting the data and release for an open challenge!
We read many recent papers on the topic, and decided to use Pyramid Stereo Matching Network (PSMNet) to prepare for the challenge, as our survey suggested that PSMNet has been chosen as the backbone for many recent works of good performence.
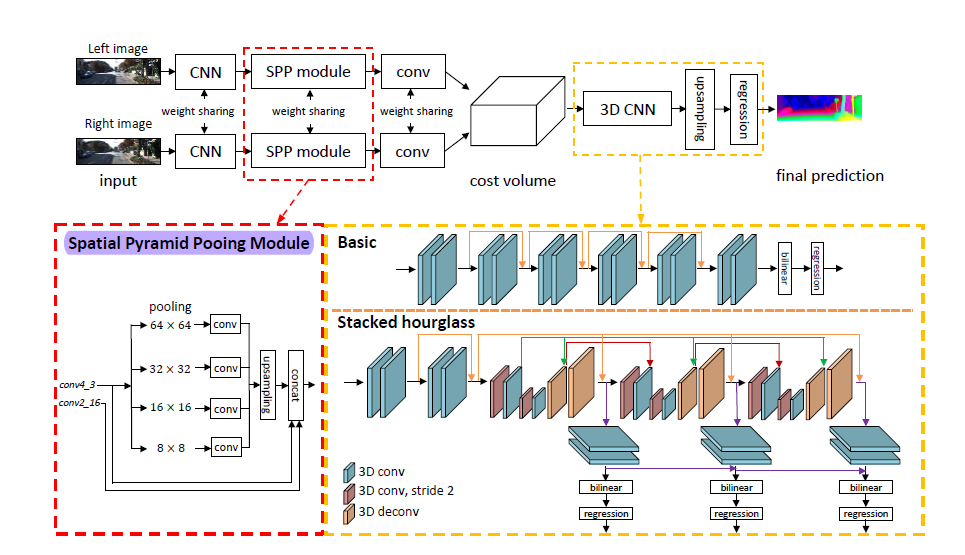
The main innovation in PSMNet is the spatial pyramid pooling module, and dilated convolution in the feature extraction stage. By using the dilated convolution during feature extraction, we have a larger receptive field in image without increasing the number of parameters. By using spatial pyramid pooling module, the network can integrate the information of image of different scale and the bilinear interpolation in SPP won’t introduce new parameters which will speed up the running time.
The multiple stacked hourglass architecture (encoder-decoder) in 3D convolution helps to differentiate the feature pair in different disparity regions.
Data Preprocessing
While visual screening through the dataset, we found out that the ground truth depth map did not perfectly match the RGB images. There is perceivable misalignment between the depth and color channels! With some investigation, we realized that the depth map is the result of interpolation with robotic kinematic between keyframes. In order to guarantee good input data, we proposed to fix the misalignment issue with data preprocessing.
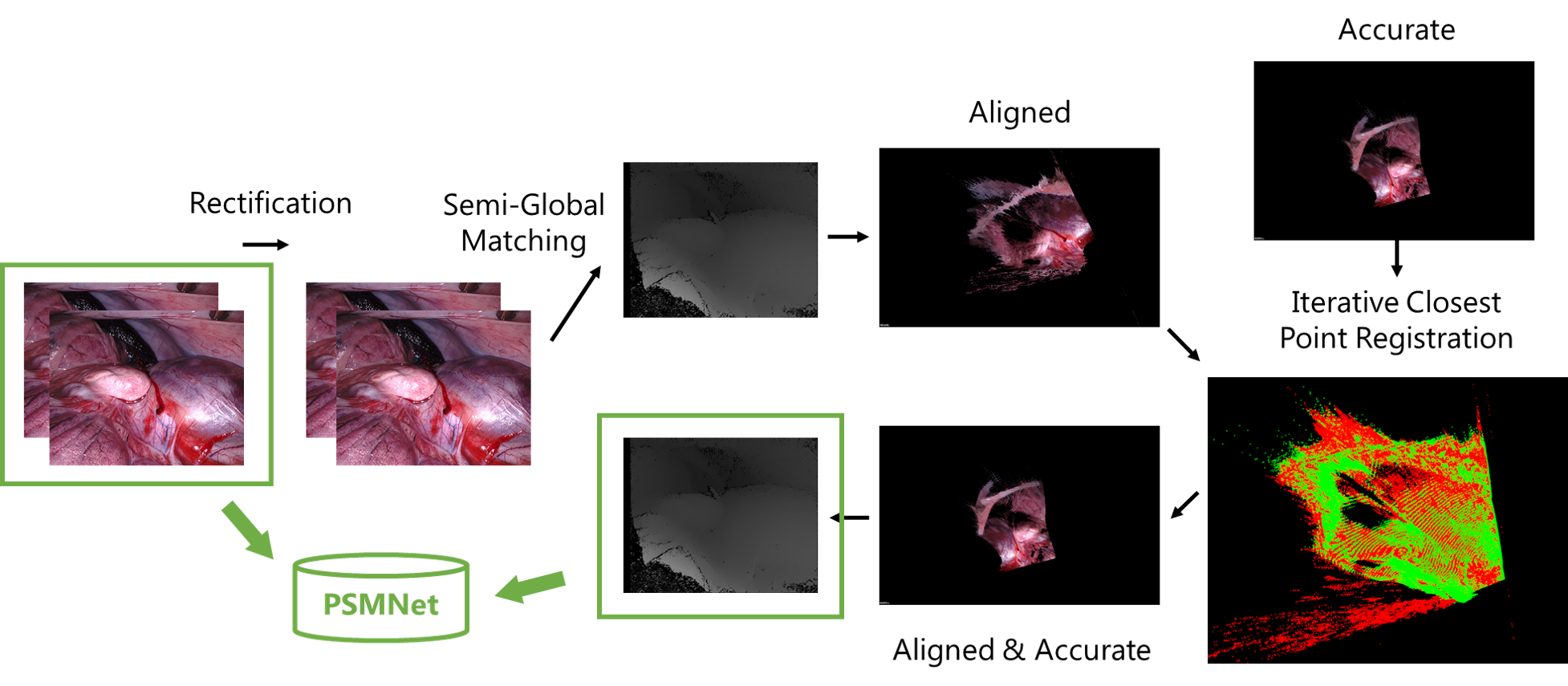
We first use traditional method (SGM) mentioned earlier in this post to estimate a point cloud from the color image pairs. Then we try to register the point cloud from SGM with the “ground truth” point cloud, with a Euclidean transformation matrix. Afterwards, we apply the transformation to correc the “ground truth”.
The data are then fed into the network for training. We use pre-trained weights from Scene Flow dataset, and then fine-tune on SCARED dataset. Here are two clips of sample visualization.
As can be seen, the reconstructed scene is smoother, without the noise from SGM. However, it does not run as efficient yet. Our team ranked 4th place in the challenge.
However, we know that there are still many challenges for such deep learning algorithm to work efficiently and reliably. It is our future work to investigate how to combine the advantages of traditional methods and deep learning. The perfromance of current algorithms are also limited by the size of dataset. There is still much to be done for the community.
Thank you for reading! 